Associate Professor in Statistics and Data Science
Editor of Journal of Statistical Software Expert use of Member of Enthusiastic for
Biography
Pierre Lafaye de Micheaux (Lafaye de Micheaux is the surname) is a Canadian/French/Swiss statistician, born in France in 1973. After two post-docs at the Centre de Recherches Mathématiques de Montréal, and at the Brain Imaging Center of McGill University, he got an Assistant Professor position at Grenoble Alps University in 2003. From 2009 to 2010, he was also an Affiliate Researcher at the Grenoble Neuroscience Institute. In 2009, he moved to the Department of Mathematics and Statistics, Université de Montréal, as an Assistant Professor. He was promoted to the Associate Professor level in 2011. From 2013 to 2014 he was a Senior Visiting Fellow to the Centre for Healthy Brain Ageing (School of Psychiatry) of UNSW Sydney. In 2015, he moved for almost two years to the French Engineering school of Statistics and Analysis of Information (CREST-ENSAI), as a Professor of Statistics. He joined the School of Mathematics and Statistics of UNSW Sydney in 2017.
Pierre Lafaye de Micheaux works on both Mathematical and Applied Statistics, as well as on the development of R packages and on industrial applications (such as Machine Learning or Deep Learning techniques). His main research interests are listed below. He (co)-leads three research groups: Dependence Measures, (Neuro)Imaging Genetics and Data Science and IoT.
Data Science, R packages, IoT, Reproducible research
Neuroscience, Imaging Genetics
Education
M.Sc in Cognitive Neuroscience, 2007
Grenoble Institute of Technology (France)
Ph.D in Statistics, 2003
Université de Montréal (Canada) and Université de Montpellier (France)
M.Sc in Biostatistics (Agronomy and Health), 1998
Université de Montpellier (France)
B.Sc in Physics and Pure Mathematics, 1996
Université de Montpellier (France)
Projects
Advice for Prospective MSc or PhD Students
I am looking to work with enjoyable, hard-working, passionate, self-motivated and autonomous students. Have a look at my publication records to see how my research looks like and if you think you could fit in (please, remember that I work in a School of Mathematics and Statistics). Feel free to contact me to discuss any research related matter! More details that you should probably read first here.
New statistical methods and computing tools to extract information from big data sets, with a specific focus on those coming from the Internet of Things
People currently working with me on one of the three projects
Below are people with whom I have the chance to work currently on these three research projects: Dependence Measures, (Neuro)Imaging Genetics and Internet of Things.
2011-2016Joseph Francois Tagne Tatsinkou, Ph.D. thesis attended on 2016/04/21, Smooth Goodness-of-fit tests in Time Series Models (joint supervision with P. Duchesne), Université de Montréal. Now, Joseph Francois Tagne Tatsinkou works as Analyst, Model Development for Canada Mortgage and Housing Corporation.
100%
2010-2013Jérémie Riou, Ph.D. thesis attended on 2013/12/11, Multiplicity of tests, and computation of sample size in clinical research (joint supervision with B. Liquet and S. Marque), Université de Bordeaux Segalen. Now Lecturer at University of Angers, France.
100%
2008-2011 Bastien Marchina, Ph.D. thesis attended on 2012/12/12, Goodness-of-fit tests based on characteristic functions (joint supervision with Gilles Ducharme, MSER Grant), Université Montpellier II. Now secondary school teacher in mathematics.
100%
M.Sc. and Honours students
2020Min Sun, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2020Kai Lin, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2020Simon Ho, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2019James Tian, Honours, School of Mathematics and Statistics, UNSW Sydney.
100%
2019Muyun (Ivan) Zou, Honours, School of Mathematics and Statistics, UNSW Sydney.
100%
2018 [Keren Zhang](), M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2018 [Han Wang](), M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2018Melinda Mortimer, Honours, School of Mathematics and Statistics, UNSW Sydney.
100%
2018Ardi Wira-Sudarmo, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2018Jasmine Bermas, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2018Minxi Feng, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
100%
2018Yunan Xu, M.Sc., School of Mathematics and Statistics, UNSW Sydney.
2013-2014Iban Harlouchet, Master at DMS, UdeM, Optimisation d’algorithme d’analyse d’empreintes olfactives (In French), Montréal.
100%
2012-2013Viet Anh Tran, Master at DMS, UdeM, Le package PoweR : un outil de recherche reproductible pour faciliter les calculs de puissance de certains tests d’hypothèses au moyen de simulations de Monte Carlo (In French), Montréal.
100%
2012-2013Marc-olivier Billette, Master at DMS, UdeM, Analyse en composantes indépendantes avec une matrice de mélange éparse (In French), Montréal.
100%
2010-2012BIGSLOTO, Master at DMS, UdeM, Approximations to the determination of the sample size for testing multiple hypotheses when r among m hypotheses must be significant (In French), Montréal.
100%
2008-2008Bastien Marchina, Master 2 ICA, On the effect of parameter estimation in limiting $\chi^2$ $U$- and $V$-statistics involving complex-valued components, attended on 2008/11/09 in Grenoble.
@article{Lafaye2020b,
author = {Geenens, Gery and {Lafaye De Micheaux}, Pierre},
title = {The Hellinger Correlation},
journal = {Journal of the American Statistical Association},
volume = {0},
number = {0},
pages = {1-43},
year = {2020},
publisher = {Taylor & Francis},
doi = {10.1080/01621459.2020.1791132},
URL = {https://doi.org/10.1080/01621459.2020.1791132},
eprint = {https://doi.org/10.1080/01621459.2020.1791132},
PDF = {lafaye2020b.pdf}
}
@article{Ducharme2020,
doi = {10.1016/j.jmva.2020.104602},
title = {A goodness-of-fit test for elliptical distributions with diagnostic capabilities},
author = {Ducharme, Gilles R. and {Lafaye De Micheaux}, Pierre},
publisher = {Elsevier Science},
journal = {Journal of Multivariate Analysis},
issn = {0047-259X,1095-7243},
year = {2020},
volume = {178},
pages = {104602},
url = {http://doi.org/10.1016/j.jmva.2020.104602},
PDF = {ducharme2020.pdf}
}
@article{Lafaye2020,
author = {Pierre {Lafaye De Micheaux}, Pierre and Mozharovskyi, Pavlo and Vimond, Myriam},
title = {Depth for Curve Data and Applications},
journal = {Journal of the American Statistical Association},
volume = {0},
number = {0},
pages = {1-17},
year = {2020},
publisher = {Taylor & Francis},
doi = {10.1080/01621459.2020.1745815},
URL = {https://doi.org/10.1080/01621459.2020.1745815},
eprint = {https://doi.org/10.1080/01621459.2020.1745815},
PDF = {lafaye2020.pdf}
}
@ARTICLE{Lafaye2019,
AUTHOR = {Pierre {Lafaye De Micheaux} and Benoit Liquet and Matthew Sutton},
TITLE = {PLS for Big Data: A unified parallel algorithm for regularised group PLS},
JOURNAL = {Statist. Surv.},
FJOURNAL = {Statistics Surveys},
YEAR = {2019},
VOLUME = {13},
PAGES = {119-149},
DOI = {10.1214/19-SS125},
url = {https://doi.org/10.1214/19-SS125},
PDF = {lafaye2019.pdf}
}
@article{Lafaye2018,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Ouimet, Frédéric},
title = {A uniform L1 law of large numbers for functions of i.i.d. random variables that are translated by a consistent estimator},
journal = {Stat. Prob. Letters},
fjournal = {Statistics \& Probability Letters},
volume = {142},
pages = {109--117},
year = {2018},
doi = {10.1016/j.spl.2018.06.006},
url = {http://doi.org/10.1016/j.spl.2018.06.006},
PDF = {lafaye2018.pdf}
}
@article {Desgagne2018,
AUTHOR = {Desgagné, Alain and {Lafaye De Micheaux}, Pierre},
TITLE = {A powerful and interpretable alternative to the Jarque–Bera test of normality based on 2nd-power skewness and kurtosis, using the Rao's score test on the APD family},
JOURNAL = {J. Appl. Stat.},
FJOURNAL = {Journal of Applied Statistics},
VOLUME = {42},
VOLUME = {45},
NUMBER = {13},
PAGES = {2307--2327},
YEAR = {2018},
DOI = {10.1080/02664763.2017.1415311},
URL = {http://dx.doi.org/10.1080/02664763.2017.1415311},
PDF = {desgagne2018.pdf}
}
@article{Bure2017,
Author={Bure, L. and Boucher, L. M. and Blumenkrantz, M. and Schob, S. and {Lafaye De Micheaux}, P. and Reinhold, C. and Gallix, B.},
Title={{{C}an magnetic resonance spectroscopy differentiate malignant and benign causes of lymphadenopathy? {A}n in-vitro approach}},
Journal={PLoS ONE},
Year={2017},
Volume={12},
Number={8},
Pages={e0182169},
PDF = {bure2017.pdf}
}
@article {Fan2017,
AUTHOR = {Fan, Yanan and {Lafaye De Micheaux}, Pierre and Penev, Spiridon and Salopek, Donna},
TITLE = {Multivariate nonparametric test of independence},
JOURNAL = {J. Multivariate Anal.},
FJOURNAL = {Journal of Multivariate Analysis},
VOLUME = {153},
YEAR = {2017},
PAGES = {189--210},
ISSN = {0047-259X},
MRCLASS = {62G20 (62G10 62H15)},
MRNUMBER = {3578846},
DOI = {10.1016/j.jmva.2016.09.014},
URL = {http://dx.doi.org/10.1016/j.jmva.2016.09.014},
PDF = {fan2017.pdf}
}
@article {Duchesne2016,
AUTHOR = {Duchesne, Pierre and {Lafaye De Micheaux}, Pierre and {Tagne Tatsinkou}, Joseph},
TITLE = {Estimating the mean and its effects on {N}eyman smooth tests of normality for {ARMA} models},
JOURNAL = {Canad. J. Statist.},
FJOURNAL = {The Canadian Journal of Statistics. La Revue Canadienne de Statistique},
VOLUME = {44},
YEAR = {2016},
NUMBER = {3},
PAGES = {241--270},
ISSN = {0319-5724},
MRCLASS = {62M10 (62F03 62F12)},
MRNUMBER = {3536197},
DOI = {10.1002/cjs.11292},
URL = {http://dx.doi.org/10.1002/cjs.11292},
PDF = {duchesne2016.pdf}
}
@article {Delorme2016,
AUTHOR = {Delorme, Phillipe and {Lafaye De Micheaux}, Pierre and Liquet,
Benoit and Riou, J\'er\'emie},
TITLE = {Type-{II} generalized family-wise error rate formulas with
application to sample size determination},
JOURNAL = {Stat. Med.},
FJOURNAL = {Statistics in Medicine},
VOLUME = {35},
YEAR = {2016},
NUMBER = {16},
PAGES = {2587--2714},
ISSN = {0277-6715},
MRCLASS = {Expansion},
MRNUMBER = {3513712},
DOI = {10.1002/sim.6909},
URL = {http://dx.doi.org/10.1002/sim.6909},
PDF = {delorme2016.pdf}
}
@article {Ducharme2016,
AUTHOR = {Ducharme, G. and {Lafaye De Micheaux}, P. and Marchina, B.},
TITLE = {The complex multinormal distribution, quadratic forms in
complex random vectors and an omnibus goodness-of-fit test for
the complex normal distribution},
JOURNAL = {Ann. Inst. Statist. Math.},
FJOURNAL = {Annals of the Institute of Statistical Mathematics},
VOLUME = {68},
YEAR = {2016},
NUMBER = {1},
PAGES = {77--104},
ISSN = {0020-3157},
MRCLASS = {60E05 (62E15 62H15)},
MRNUMBER = {3440215},
DOI = {10.1007/s10463-014-0486-5},
URL = {http://dx.doi.org/10.1007/s10463-014-0486-5},
PDF = {ducharme2016.pdf}
}
@article{Lafaye2016a,
author = {{Lafaye De Micheaux}, Pierre and Tran, Viet},
title = {PoweR: A Reproducible Research Tool to Ease Monte Carlo Power Simulation Studies for Goodness-of-fit Tests in R},
journal = {Journal of Statistical Software},
volume = {69},
number = {1},
year = {2016},
keywords = {reproducible research; Monte Carlo; goodness-of-fit test; power study; R},
abstract = {The PoweR package aims to help obtain or verify empirical power studies for goodnessof-fit tests for independent and identically distributed data. The current version of our package is only valid for simple null hypotheses or for pivotal test statistics for which the set of critical values does not depend on a particular choice of a null distribution (and on nuisance parameters) under the non-simple null case. We also assume that the distribution of the test statistic is continuous. As a reproducible research computational tool it can be viewed as helping to simply reproducing (or detecting errors in) simulation results already published in the literature. Using our package helps also in designing new simulation studies. The empirical levels and powers for many statistical test statistics under a wide variety of alternative distributions can be obtained quickly and accurately using a C/C++ and R environment. The parallel package can be used to parallelize computations when a multicore processor is available. The results can be displayed using LATEX tables or specialized graphs, which can be directly incorporated into a report. This article gives an overview of the main design aims and principles of our package, as well as strategies for adaptation and extension. Hands-on illustrations are presented to help new users in getting started.},
issn = {1548-7660},
pages = {1--44},
doi = {10.18637/jss.v069.i03},
url = {https://www.jstatsoft.org/index.php/jss/article/view/v069i03},
PDF = {lafaye2016.pdf}
}
@article{Bilodeau2015,
author = {Bilodeau, Martin and {Lafaye De Micheaux}, Pierre and Mahdi, Smail},
title = {The R Package groc for Generalized Regression on Orthogonal Components},
journal = {Journal of Statistical Software},
volume = {65},
number = {1},
year = {2015},
keywords = {},
abstract = {The R package groc for generalized regression on orthogonal components contains functions for the prediction of q responses using a set of p predictors. The primary building block is the grid algorithm used to search for components (projections of the data) which are most dependent on the response. The package offers flexibility in the choice of the dependence measure which can be user-defined. The components are found sequentially. A first component is obtained and a smooth fit produces residuals. Then, a second component orthogonal to the first is found which is most dependent on the residuals, and so on. The package can handle models with more than one response. A panoply of models can be achieved through package groc: robust multiple or multivariate linear regression, nonparametric regression on orthogonal components, and classical or robust partial least squares models. Functions for predictions and cross-validation are available and helpful in model selection. The merit of a fit through cross-validation can be assessed with the predicted residual error sum of squares or the predicted residual error median absolute deviation which is more appropriate in the presence of outliers.},
issn = {1548-7660},
pages = {1--29},
doi = {10.18637/jss.v065.i01},
url = {https://www.jstatsoft.org/index.php/jss/article/view/v065i01},
PDF = {bilodeau2015.pdf}
}
@book{Lafaye2016b,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Drouilhet, R\'emy and Liquet,
Benoit},
TITLE = {Perangkat Lukan R - dan Analisis Statistika},
PUBLISHER = {},
YEAR = {2016},
PAGES = {},
ISBN = {},
MRCLASS = {62-01 (62-07 62D05 62Exx 62G15 62Hxx 62J10 68-04)},
DOI = {},
URL = {},
}
@book{Lafaye2015,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Drouilhet, R\'emy and Liquet,
Benoit and Pan, Dondong and Tang, Niansheng and Li, Qizhai},
TITLE = {R 软件及统计分析},
PUBLISHER = {Higher Education Press},
YEAR = {2015},
PAGES = {576},
ISBN = {7040419505 ; 9787040419504},
MRCLASS = {62-01 (62-07 62D05 62Exx 62G15 62Hxx 62J10 68-04)},
URL = {http://product.dangdang.com/23690324.html},
PDF = {livreRchinese20jan2014.pdf}
}
@article{Lafaye2014a,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Liquet, Benoit and Marque,
S\'ebastien and Riou, J\'er\'emie},
TITLE = {Power and sample size determination in clinical trials with
multiple primary continuous correlated endpoints},
JOURNAL = {J. Biopharm. Statist.},
FJOURNAL = {Journal of Biopharmaceutical Statistics},
VOLUME = {24},
YEAR = {2014},
NUMBER = {2},
PAGES = {378--397},
ISSN = {1054-3406},
MRCLASS = {Expansion},
MRNUMBER = {3196147},
DOI = {10.1080/10543406.2013.860156},
URL = {http://dx.doi.org/10.1080/10543406.2013.860156},
PDF = {lafaye2014.pdf}
}
@book {Lafaye2014b,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Drouilhet, Rémy and Liquet,
Benoit},
TITLE = {Le logiciel R, Maîtriser le langage - Effectuer des analyses (bio)statistiques},
SERIES = {Collection: Statistique et probabilités appliquées},
NOTE = {In French},
PUBLISHER = {Springer France},
YEAR = {2014},
PAGES = {674},
ISBN = {9782817805344},
MRCLASS = {62-01 (62-07 62D05 62Exx 62G15 62Hxx 62J10 68-04)},
URL = {https://editions.lavoisier.fr/mathematiques/le-logiciel-r-2-ed/lafaye-de-michaux//livre/9782817805344},
PDF = {livreR2014.pdf}
}
@book {Lafaye2013,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Drouilhet, R\'emy and Liquet,
Benoit},
TITLE = {The {R} software},
SERIES = {Statistics and Computing},
NOTE = {Fundamentals of programming and statistical analysis,
Translated from French by Robin Ryder},
PUBLISHER = {Springer, New York},
YEAR = {2013},
PAGES = {xxxviii+628},
ISBN = {978-1-4614-9019-7; 978-1-4614-9020-3},
MRCLASS = {62-01 (62-07 62D05 62Exx 62G15 62Hxx 62J10 68-04)},
MRNUMBER = {3308351},
DOI = {10.1007/978-1-4614-9020-3},
URL = {http://dx.doi.org/10.1007/978-1-4614-9020-3},
PDF = {bookR2013.pdf}
}
@article {Duchesne2013,
AUTHOR = {Duchesne, Pierre and {Lafaye De Micheaux}, Pierre},
TITLE = {Distributions for residual autocovariances in parsimonious
periodic vector autoregressive models with applications},
JOURNAL = {J. Time Series Anal.},
FJOURNAL = {Journal of Time Series Analysis},
VOLUME = {34},
YEAR = {2013},
NUMBER = {4},
PAGES = {496--507},
ISSN = {0143-9782},
MRCLASS = {62M10 (62F12 62M07)},
MRNUMBER = {3070871},
MRREVIEWER = {Nazar\~A\copyright{} Mendes Lopes},
DOI = {10.1111/jtsa.12026},
URL = {http://dx.doi.org/10.1111/jtsa.12026},
PDF = {duchesne2013.pdf}
}
@article {Desgagne2013,
AUTHOR = {Desgagné, Alain and {Lafaye De Micheaux}, Pierre and Leblanc,
Alexandre},
TITLE = {Test of normality against generalized exponential power
alternatives},
JOURNAL = {Comm. Statist. Theory Methods},
FJOURNAL = {Communications in Statistics. Theory and Methods},
VOLUME = {42},
YEAR = {2013},
NUMBER = {1},
PAGES = {164--190},
ISSN = {0361-0926},
MRCLASS = {62F03 (62E20)},
MRNUMBER = {3004652},
MRREVIEWER = {Jingjing Wu},
DOI = {10.1080/03610926.2011.577548},
URL = {http://dx.doi.org/10.1080/03610926.2011.577548},
PDF = {desgagne2013.pdf}
}
@article{Lafaye2012a,
author = {{Lafaye De Micheaux}, Pierre and Lemaire, Vincent},
title = {Sample Size Determination and Statistical Hypothesis Testing for Core Centration in Press Coated Tablets},
journal = {Open Journal of Statistics},
volume = {2},
number = {3},
year = {2012},
keywords = {Core Centration; Statistical Hypothesis Testing; Dry-Coated Tablets; Sample Size},
abstract = {A novel statistical approach to evaluate the manufacturing quality of press coated tablets in terms of the centering of their core is presented. We also provide a formula to determine the necessary sample size. This approach is applied to real data.},
issn = {2161-7198},
pages = {269--273},
doi = {10.4236/ojs.2012.23032},
url = {http://www.scirp.org/jouRNAl/PaperInformation.aspx?PaperID=20378},
PDF = {lafaye2012a.pdf}
}
@article {Lafaye2012b,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Léger, Christian},
TITLE = {A law of the single logarithm for weighted sums of arrays
applied to bootstrap model selection in regression},
JOURNAL = {Statist. Probab. Lett.},
FJOURNAL = {Statistics \& Probability Letters},
VOLUME = {82},
YEAR = {2012},
NUMBER = {5},
PAGES = {965--971},
ISSN = {0167-7152},
MRCLASS = {60F15 (60B12 60G50 62G09 62J05)},
MRNUMBER = {2910044},
DOI = {10.1016/j.spl.2012.01.018},
URL = {http://dx.doi.org/10.1016/j.spl.2012.01.018},
PDF = {lafaye2012b.pdf}
}
@book {Lafaye2011,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Drouilhet, Rémy and Liquet,
Benoit},
TITLE = {Le logiciel R, Maîtriser le langage - Effectuer des analyses statistiques},
SERIES = {Collection: Statistique et probabilités appliquées},
NOTE = {In French},
PUBLISHER = {Springer France},
YEAR = {2011},
PAGES = {xxxvii+488},
ISBN = {978-2-8178-0114-8 ; 978-2-8178-0115-5},
MRCLASS = {62-01 (62-07 62D05 62Exx 62G15 62Hxx 62J10 68-04)},
URL = {http://www.springer.com/la/book/9782817801148},
PDF = {livreR2011.pdf}
}
@article{Bordier2011,
author = {Bordier, Cécile and Dojat, Michel and {Lafaye De Micheaux}, Pierre},
title = {Temporal and Spatial Independent Component Analysis for fMRI Data Sets Embedded in the AnalyzeFMRI R Package},
journal = {Journal of Statistical Software},
volume = {44},
number = {1},
year = {2011},
keywords = {},
abstract = {For statistical analysis of functional magnetic resonance imaging (fMRI) data sets, we propose a data-driven approach based on independent component analysis (ICA) implemented in a new version of the AnalyzeFMRI R package. For fMRI data sets, spatial dimension being much greater than temporal dimension, spatial ICA is the computationally tractable approach generally proposed. However, for some neuroscientific applications, temporal independence of source signals can be assumed and temporal ICA becomes then an attractive exploratory technique. In this work, we use a classical linear algebra result ensuring the tractability of temporal ICA. We report several experiments on synthetic data and real MRI data sets that demonstrate the potential interest of our R package.},
issn = {1548-7660},
pages = {1--24},
doi = {10.18637/jss.v044.i09},
url = {https://www.jstatsoft.org/index.php/jss/article/view/v044i09},
PDF = {bordier2011.pdf}
}
@article {Duchesne2010,
AUTHOR = {Duchesne, Pierre and {Lafaye De Micheaux}, Pierre},
TITLE = {Computing the distribution of quadratic forms: further
comparisons between the {L}iu-{T}ang-{Z}hang approximation and
exact methods},
JOURNAL = {Comput. Statist. Data Anal.},
FJOURNAL = {Computational Statistics \& Data Analysis},
VOLUME = {54},
YEAR = {2010},
NUMBER = {4},
PAGES = {858--862},
ISSN = {0167-9473},
MRCLASS = {Expansion},
MRNUMBER = {2580921},
DOI = {10.1016/j.csda.2009.11.025},
URL = {http://dx.doi.org/10.1016/j.csda.2009.11.025},
PDF = {duchesne2010.pdf}
}
@article {Lafaye2009a,
AUTHOR = {{Lafaye De Micheaux}, Pierre and Liquet, Benoit},
TITLE = {Understanding convergence concepts: a visual-minded and
graphical simulation-based approach},
JOURNAL = {Amer. Statist.},
FJOURNAL = {The American Statistician},
VOLUME = {63},
YEAR = {2009},
NUMBER = {2},
PAGES = {173--178},
ISSN = {0003-1305},
MRCLASS = {Expansion},
MRNUMBER = {2750078},
DOI = {10.1198/tas.2009.0032},
URL = {http://dx.doi.org/10.1198/tas.2009.0032},
PDF = {lafaye2009a.pdf}
}
@article {Bilodeau2009,
AUTHOR = {Bilodeau, M. and {Lafaye De Micheaux}, P.},
TITLE = {{$A$}-dependence statistics for mutual and serial independence
of categorical variables},
JOURNAL = {J. Statist. Plann. Inference},
FJOURNAL = {Journal of Statistical Planning and Inference},
VOLUME = {139},
YEAR = {2009},
NUMBER = {7},
PAGES = {2407--2419},
ISSN = {0378-3758},
MRCLASS = {62H15 (62G09)},
MRNUMBER = {2508002},
DOI = {10.1016/j.jspi.2008.11.006},
URL = {http://dx.doi.org/10.1016/j.jspi.2008.11.006},
PDF = {bilodeau2009.pdf}
}
@Article{Coeurjolly2009a,
author = {Coeurjolly, J. F. and Drouilhet, R. and {Lafaye De Micheaux}, P. and Robineau, J. F.},
title = {{asympTest}: A Simple {R} Package for Classical Parametric Statistical Tests and Confidence Intervals in Large Samples},
journal = {The R Journal},
year = 2009,
volume = 1,
number = 2,
pages = {26--30},
month = dec,
url = {http://journal.r-project.org/archive/2009-2/},
PDF = {coeurjolly2009.pdf}
}
@Article{Lafaye2009b,
author = {{Lafaye De Micheaux}, Pierre and Liquet, Benoit},
title = {{ConvergenceConcepts}: an {R} Package to Investigate-Various-Modes-of-Convergence},
journal = {The R Journal},
year = 2009,
volume = 1,
number = 2,
pages = {18--25},
month = dec,
url = {http://journal.r-project.org/archive/2009-2/},
PDF = {lafaye2009b.pdf}
}
@article {Beran2007,
AUTHOR = {Beran, R. and Bilodeau, M. and {Lafaye De Micheaux}, P.},
TITLE = {Nonparametric tests of independence between random vectors},
JOURNAL = {J. Multivariate Anal.},
FJOURNAL = {Journal of Multivariate Analysis},
VOLUME = {98},
YEAR = {2007},
NUMBER = {9},
PAGES = {1805--1824},
ISSN = {0047-259X},
MRCLASS = {62H15 (60F05 62G09 62G10)},
MRNUMBER = {2392434},
MRREVIEWER = {Natalie Neumeyer},
DOI = {10.1016/j.jmva.2007.01.009},
URL = {http://dx.doi.org/10.1016/j.jmva.2007.01.009},
PDF = {beran2007.pdf}
}
@article {Bilodeau2005,
AUTHOR = {Bilodeau, M. and {Lafaye De Micheaux}, P.},
TITLE = {A multivariate empirical characteristic function test of
independence with normal marginals},
JOURNAL = {J. Multivariate Anal.},
FJOURNAL = {Journal of Multivariate Analysis},
VOLUME = {95},
YEAR = {2005},
NUMBER = {2},
PAGES = {345--369},
ISSN = {0047-259X},
MRCLASS = {62H15 (60F05 62E20 62M99)},
MRNUMBER = {2170401},
MRREVIEWER = {B\~A\copyright{}la Uhrin},
DOI = {10.1016/j.jmva.2004.08.011},
URL = {http://dx.doi.org/10.1016/j.jmva.2004.08.011},
PDF = {bilodeau2005.pdf}
}
@article {Ducharme2004,
AUTHOR = {Ducharme, Gilles R. and {Lafaye De Micheaux}, Pierre},
TITLE = {Goodness-of-fit tests of normality for the innovations in
{ARMA} models},
JOURNAL = {J. Time Ser. Anal.},
FJOURNAL = {Journal of Time Series Analysis},
VOLUME = {25},
YEAR = {2004},
NUMBER = {3},
PAGES = {373--395},
ISSN = {0143-9782},
MRCLASS = {62M10},
MRNUMBER = {2062680},
DOI = {10.1111/j.1467-9892.2004.01875.x},
URL = {http://dx.doi.org/10.1111/j.1467-9892.2004.01875.x},
PDF = {ducharme2004.pdf}
}
@Article{Nicoli2013,
Author = {Nicoli, F. and {Lafaye De Micheaux}, P. and Girard, N.},
Title = {{{P}erfusion-weighted imaging-derived collateral flow index is a predictor of {M}{C}{A} {M}1 recanalization after i.v. thrombolysis}},
Journal = {AJNR Am J Neuroradiol},
Year = {2013},
Volume = {34},
Number = {1},
Pages = {107--114},
Month = {Jan},
URL = {https://doi.org/10.3174/ajnr.A3174},
PDF = {nicoli2013.pdf}
}
@Article{Tabelow2011,
Author = {Tabelow, K. and Clayden, J. D. and {Lafaye De Micheaux}, P. and Polzehl, J. and Schmid, V. J. and Whitcher, B.},
Title = {{{I}mage analysis and statistical inference in neuroimaging with {R}}},
Journal = {Neuroimage},
Year = {2011},
Volume = {55},
Number = {4},
Pages = {1686--1693},
Month = {Apr},
URL = {https://doi.org/10.1016/j.neuroimage.2011.01.013},
PDF = {tabelow2011.pdf}
}
@Article{Cenier2008,
Author = {Cenier, T. and Amat, C. and Litaudon, P. and Garcia, S. and {Lafaye De Micheaux}, P. and Liquet, B. and Roux, S. and Buonviso, N.},
Title = {{{O}dor vapor pressure and quality modulate local field potential oscillatory patterns in the olfactory bulb of the anesthetized rat}},
Journal = {Eur. J. Neurosci.},
Year = {2008},
Volume = {27},
Number = {6},
Pages = {1432--1440},
Month = {Mar},
URL = {https://doi.org/10.1111/j.1460-9568.2008.06123.x},
PDF = {cenier2008.pdf}
}
@Article{Dubois2007,
Author = {Dubois, M. and {Lafaye De Micheaux}, P. and Noel, M. P. and Valdois, S.},
Title = {{{P}reorthographical constraints on visual word recognition: evidence from a case study of developmental surface dyslexia}},
Journal = {Cogn Neuropsychol},
Year = {2007},
Volume = {24},
Number = {6},
Pages = {623--660},
Month = {Sep},
URL = {https://doi.org/10.1080/02643290701617330},
PDF = {dubois2007.pdf}
}
@Article{Wen2016,
Author = {Wen, W. and Thalamuthu, A. and Mather, K. A. and Zhu, W. and Jiang, J. and {Lafaye De Micheaux}, P. and Wright, M. J. and Ames, D. and Sachdev, P. S.},
Title = {{{D}istinct {G}enetic {I}nfluences on {C}ortical and {S}ubcortical {B}rain {S}tructures}},
Journal = {Sci Rep},
Year = {2016},
Volume = {6},
Pages = {32760},
Month = {Sep},
URL = {https://doi.org/10.1038/srep32760},
PDF = {wen2016.pdf}
}
@Article{Liquet2016,
Author = {Liquet, B. and {Lafaye De Micheaux}, P. and Hejblum, B. P. and Thiebaut, R.},
Title = {{{G}roup and sparse group partial least square approaches applied in genomics context}},
Journal = {Bioinformatics},
Year = {2016},
Volume = {32},
Number = {1},
Pages = {35--42},
Month = {Jan},
URL = {https://doi.org/10.1093/bioinformatics/btv535},
PDF = {liquet2016.pdf}
}
@article{Haddadi2014,
author = {Haddadi, Ahmed and Ledmani, Mohamed and Gainier, Marc and Hubert, Hubert and {Lafaye De Micheaux}, Pierre},
title = {Comparing the APACHE II, SOFA, LOD, and SAPS II scores in patients who have developed a nosocomial infection},
journal = {Bangladesh Critical Care Journal},
volume = {2},
number = {1},
year = {2014},
keywords = {intensive care; risk factors; nosocomial infections; ICU mortality; severity scores},
abstract = {Background: There have been numerous scores intended to evaluate the severity of patients’ condition upon admission and during their intensive care unit (ICU) stay. However, to our knowledge, no study has ever evaluated the predictive abilities of these scores among nosocomial patients during their ICU stay. The aim of our study is to compare the predictive performances of the Acute Physiology, and, Chronic Health Evaluation (APACHE II) score, Simplified Acute Physiologic Score (SAPS II), Logistic Organ Dysfunction (LOD), and Sequential Organ Failure Assessment (SOFA) scores among intensive care patients who have developed a nosocomial infection. Methods: The study is monocentric and retrospective. The APACHE II, SAPS II, LOD, and SOFA scores were reported from the third day of the patient’s hospital stay, preceding the diagnosis of the first nosocomial event up to the third post diagnosis day. Results: Out of 46 patients contracting at least one ICU-acquired infection, the multiple analyses indicated that on the day of diagnosis, the SOFA score is the most predictive (odds ratio [OR]: 12.3; 95% confidence interval [CI]: 2.33–64.91). The second most predictive was the APACHE II score (OR: 8.29; 95% CI: 1.43–48.14). The third and fourth most predictive were the LOD score (OR: 4.06; 95% CI: 0.81–20.26) and the SAPS II score (OR: 2.26; 95% CI: 0.55–9.24), respectively. Conclusion: The analysis of the receiver operating characteristic areas under the curve of the reported scores in the present study showed that the best predictive performance is in favor of the SOFA score. DOI: http://dx.doi.org/10.3329/bccj.v2i1.19949 Bangladesh Crit Care J March 2014; 2 (1): 4-9},
issn = {2307-7654},
url = {http://www.banglajol.info/index.php/BCCJ/article/view/19949},
pages = {4--9},
PDF = {haddadi2014.pdf}
}
@Article{Marteau2013,
Author = {Marteau, P. and Guyonnet, D. and {Lafaye De Micheaux}, P. and Gelu, S.},
Title = {{{A} randomized, double-blind, controlled study and pooled analysis of two identical trials of fermented milk containing probiotic {B}ifidobacterium lactis {C}{N}{C}{M} {I}-2494 in healthy women reporting minor digestive symptoms}},
Journal = {Neurogastroenterol. Motil.},
Year = {2013},
Volume = {25},
Number = {4},
Pages = {331-e252},
Month = {Apr},
URL = {http://dx.doi.org/10.1111/nmo.12078},
PDF = {marteau2013.pdf}
}
@MastersThesis{Lafaye1998,
author = {{Lafaye De Micheaux}, P.},
title = {Test de normalité pour les résidus d'un modèle ARMA},
school = {Université Montpellier II et École Nationale Supérieure Agronomique de Montpellier},
year = {1998},
organization = {},
type = {MSc thesis (DEA)},
month = {June},
URL = {http://www.sudoc.fr/010676619},
PDF = {dea.pdf}
}
@TechReport{Ducharme2002,
author = {Ducharme, G. and {Lafaye De Micheaux}, P.},
title = {Goodness-of-fit tests of normality for the innovations in ARMA models},
institution = {Université Montpellier II},
year = 2002,
type = {Technical report},
number = {02-02},
PDF = {techjtsa2002.pdf}
}
@MastersThesis{Lafaye2007,
author = {{Lafaye De Micheaux}, P.},
title = {Méthodes statistiques multivariées en IRMF},
school = {Grenoble Institute of Technology},
year = {2007},
organization = {},
type = {MSc thesis},
month = {June},
PDF = {master2007.pdf}
}
@TechReport{Coeurjolly2009b,
author = {Coeurjolly, J.-F. and Drouilhet, R. and {Lafaye De Micheaux}, P. and Robineau, J.-F.},
title = {asympTest: an R package for performing parametric statistical tests and confidence intervals based on the central limit theorem},
institution = {Laboratoire Jean Kuntzmann. Université de Grenoble},
year = {2009},
type = {Technical report},
number = {hal-00358375},
month = {June},
PDF = {techRjourn2009.pdf}
}
@TechReport{Coeurjolly2009c,
author = {Coeurjolly, J.-F. and Drouilhet, R. and {Lafaye De Micheaux}, P. and Robineau, J.-F.},
title = {asympTest: an R package for performing parametric statistical tests and confidence intervals based on the central limit theorem},
institution = {Universit{\'e} de Grenoble},
year = {2009},
type = {ArXiv},
number = {0902.0506v2},
month = {February},
PDF = {techRjourn2009c.pdf}
}
@TechReport{Desgagne2018b,
author = {Desgagn{\'e}, A. and {Lafaye De Micheaux}, P. and Ouimet, F.},
title = {Asymptotic law of a modified score statistic
for the asymmetric power distribution with unknown location and scale parameters},
institution = {UQAM},
year = 2018,
type = {ArXiv},
number = {1809.02852v1},
month = {September},
PDF = {techtechnometrics2018.pdf}}
@TechReport{Dcuharme2019,
author = {Ducharme, G. and {Lafaye De Micheaux}, P.},
title = {A goodness-of-fit test for elliptical distributions with diag-
nostic capabilities},
institution = {Universit{\'e} de Montpellier},
year = 2019,
type = {ArXiv},
number = {1902.03622v1},
month = {February},
PDF = {techjmva2019.pdf}}
@TechReport{Duchesne2019,
author = {Duchesne, P. and {Lafaye De Micheaux}, P.},
title = {On strong consistency and asymptotic
normality of one-step Gauss-Newton estimators in ARMA time series models},
institution = {CRM},
year = 2019,
type = {Technical Report},
number = {CRM-3371},
month = {December},
PDF = {techstatistics2019.pdf}}
@TechReport{Desgagne2011,
author = {Desgagn{\'e}, A. and {Lafaye De Micheaux}, P. and Leblanc, A.},
title = {Test of normality against generalized exponential power alternatives},
institution = {CRM},
year = 2011,
type = {Technical Report},
number = {CRM-3314},
month = {March},
PDF = {techcrm2011.pdf}}
@TechReport{Geenens2019,
author = {Geenens, G. and {Lafaye De Micheaux}, P.},
title = {The Hellinger Correlation},
institution = {UNSW Sydney},
year = 2019,
type = {ArXiv},
number = {1810.10276v4},
month = {December},
PDF = {techjasa2019.pdf}}
@TechReport{Lafaye2020,
author = {{Lafaye De Micheaux}, P. and Mozharovskyi, P. and Vimond, M.},
title = {Depth for curve data and applications},
institution = {UNSW Sydney},
year = 2020,
type = {ArXiv},
number = {1901.00180v2},
month = {February},
PDF = {techjasa2020.pdf}}
@TechReport{Bordier2010,
author = {Bordier, C. and Dojat, M. and {Lafaye De Micheaux}, P.},
title = {Temporal and Spatial Independent Component Analysis for fMRI data sets embedded in a R package},
institution = {Grenoble Neuroscience Institute},
year = {2010},
type = {ArXiv},
number = {012.0269v1},
month = {December},
PDF = {techjss2011.pdf}
}
@TechReport{Tabelow2010,
author = {Tabelow, K. and Clayden, J.D. and {Lafaye De Micheaux}, P. and Polzehl, J. and Schmid, V.J. and Whitcher, B.},
title = {Image Analysis and Statistical Inference in Neuroimaging with R},
institution = {Weierstrass Institute for Applied Analysis and Stochastics},
year = {2010},
type = {Technical Report},
number = {1578},
month = {December},
PDF = {techneuroimage2011.pdf}
}
@TechReport{Lafaye2017b,
author = {{Lafaye De Micheaux}, P. and {Liquet}, B. and {Sutton}, M.},
title = {A Unified Parallel Algorithm for Regularized Group PLS Scalable to Big Data},
institution = {UNSW Sydney},
year = 2017,
type = {ArXiv e-prints},
number = {1702.07066},
month = {feb},
PDF = {lafaye2017b.pdf},
URL = {https://arxiv.org/abs/1702.07066}
}
Lafaye de Micheaux P. Test de normalité pour les résidus d'un modèle ARMA. Master's thesis (DEA), Université Montpellier II et École Nationale Supérieure Agronomique de Montpellier, 127 pages, June 1998.
Ducharme G. and Lafaye de Micheaux P. Goodness-of-fit tests of normality for the innovations in ARMA models. Technical report number 02-02, Groupe de biostatistique et d'analyse des systèmes, Université Montpellier II, 34 pages, February 2002.
Lafaye de Micheaux P. Méthodes statistiques multivariées en IRMF. Mémoire de Master 2 Recherche, Institut National Polytechnique de Grenoble, 92 pages, June 2007. (In french).
Coeurjolly J.-F., Drouilhet, R., Lafaye de Micheaux P. et Robineau, J.-F. (February 2009). asympTest: an R package for performing parametric statistical tests and confidence intervals based on the central limit theorem. Technical report hal-00358375. Laboratoire Jean Kuntzmann. Université de Grenoble, 18 pages.
Bordier C., Dojat, M. and Lafaye de Micheaux P. (December 2010). Temporal and Spatial Independent Component Analysis for fMRI data sets embedded in a R package, arXiv 1012.0269v1, 23 pages.
Tabelow K., Clayden J.D., Lafaye de Micheaux P., Polzehl J., Schmid V.J., Whitcher B. (December 2010). Image Analysis and Statistical Inference in Neuroimaging with R, Technical report 1578, Weierstrass Institute for Applied Analysis and Stochastics, 9 pages.
[1] Test de normalité pour les résidus d'un modèle ARMA, June 1998.
Abstract: The results contained in this document cast a new light on the important problem of testing the residuals of an ARMA model. Indeed, the validation stage when fitting a model to data, is the determinant step in selecting the best model. The Box and Jenkin's three stages method ends with the validation step which requires the portmanteau test. An advantage of such portmanteau tests is that they pool information from the correlations at different lags. However, a real disadvantage is that they frequently fail to reject poorly fitting models. In practice, they are more useful in disqualifying unsatisfactory models than for selecting the best-fitting model among closely competing candidates. We need to stress that if it can be assumed that the white noise process of an ARMA process is Gaussian, then stronger conclusions can be drawn from the fitted model. For example, not is it only possible to specify an estimated mean squarred error for predicted values, but asymptotic prediction confidence bounds can also be computed. This being so, we propose to replace the portmanteau test with the one we developp here which is targeted at testing normality.
Localisation: Bibliothèque de l'Université Montpellier II. Author : Lafaye de Micheaux, Pierre Title : Test de normalité pour les résidus d'un modèle ARMA / Pierre Lafaye de Micheaux Editor : Montpellier : Université Montpellier II Sciences et Techniques du Languedoc, [1998] Collation : 127 f. ; 30 cm Note : thèse Mém. D.E.A. : Biostatistique-Option Agron.-Santé : Montpellier 2 : 1998 Subject : Biométrie -- thèses Link: Link to bibliographical entry
[2] Goodness-of-fit tests of normality for the innovations in ARMA models, Février 2002.
Technical report number 02-02. Groupe de Biostatistique et d'Analyse des systèmes. Université Montpellier II
Abstract: In this paper, we propose a goodness-of-fit test of normality for the innovations of an ARMA(p,q) model with known mean or trend. The test is based on the data-driven smooth test approach and is simple to perform. An extensive simulation study is conducted to see if, for moderate sample sizes, the test holds its level throughout the parameter space. The power of the procedure is also explored by simulation. It is found that our test is generally more powerful than existing tests while holding its level throughout most of the parameter space and thus, can be recommended. This meshes with theoretical results showing the superiority of the data-driven smooth test approach in related contexts.
[3] Méthodes statistiques multivariées en IRMF, June 2007. (In french).
Abstract: The functional magnetic resonance imaging (fMRI) is a new neuroimaging technique that can localize neuronal activiy with a great spatial precision and with a good temporal precision. To detect activated areas in the brain, this method uses local blood oxygenation variations which are reflected by small variations in a certain kind of images obtained by magnetic resonance. The ability to obtain a functional map of the brain non invasively gives new opportunities to disentangle mysteries of the human brain. In this thesis, we describe some non parametric methods of multivariate analysis of fMRI data: Principal component analysis, Independant component analysis and Projection pursuit. We also try to explain the links between these methods, the different views one can have on them and we deal with underlying spatial and temporal aspects. We also provide a computer tool that can simulate, in a very simplified way, fMRI brain signals. This tool enable one to artificially generate fMRI data for which we control many parameters. It will serve as a basis to compare quantitatively the statistical methods presented. We also apply these various statistical methods on a real data set obtained from a human visual fMRI experiment. At least, we propose various avenues of research that could be explored to pursue this preliminary work.
[4] asympTest: an R package for performing parametric statistical tests and confidence intervals based on the central limit theorem, February 2009.
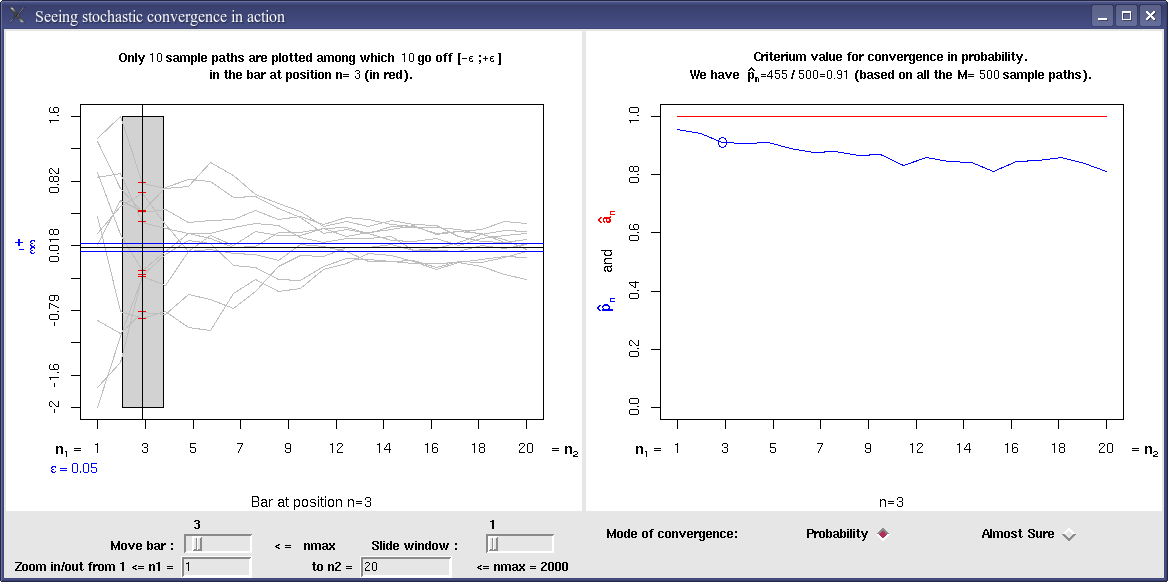
Abstract: This paper describes an R package implementing large sample tests and confidence intervals (based on the central limit theorem) for various parameters. The one and two sample mean and variance contexts are considered. The statistics for all the tests are expressed in the same form, which facilitates their presentation. In the variance parameter cases, the asymptotic robustness of the classical tests depends on the departure of the data distribution from normality measured in terms of the kurtosis of the distribution.
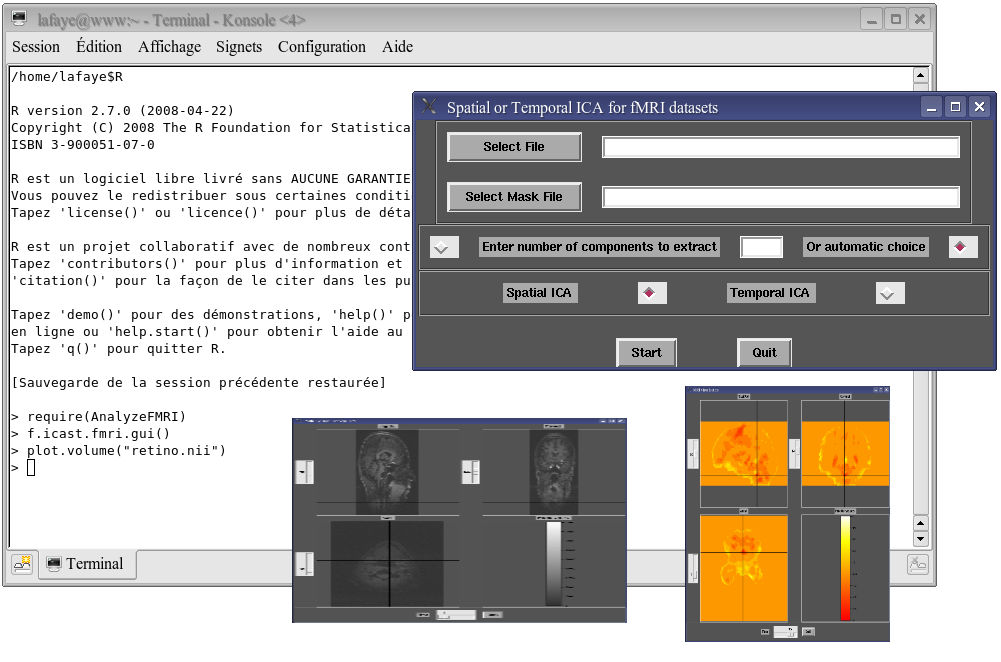
[5] Temporal and Spatial Independent Component Analysis for fMRI data sets embedded in a R package, December 2010.
Abstract: For statistical analysis of functional Magnetic Resonance Imaging (fMRI) data sets, we propose a data-driven approach based on Independent Component Analysis (ICA) im- plemented in a new version of the AnalyzeFMRI R package. For fMRI data sets, spatial dimension being much greater than temporal dimension, spatial ICA is the tractable ap- proach generally proposed. However, for some neuroscientific applications, temporal inde- pendence of source signals can be assumed and temporal ICA becomes then an attracting exploratory technique. In this work, we use a classical linear algebra result ensuring the tractability of temporal ICA. We report several experiments on synthetic data and real MRI data sets that demonstrate the potential interest of our R package.
[6] Image Analysis and Statistical Inference in Neuroimaging with R, December 2010.
Abstract: R is a language and environment for statistical computing and graphics. It can be considered an alternative implementation of the S language developed in the 1970s and 1980s for data analysis and graphics (Becker and Chambers, 1984; Becker et al., 1988). The R language is part of the GNU project and offers versions that compile and run on almost every major operating system currently available. We highlight several R packages built specifically for the analysis of neuroimaging data in the context of functional MRI, diffusion tensor imaging, and dynamic contrast-enhanced MRI. We review their methodology and give an overview of their capabilities for neuroimaging. In addition we summarize some of the current activities in the area of neuroimaging software development in R.
Auteur: Lafaye de Micheaux Pierre. Titre: Tests d’indépendance en analyse multivariée et tests de normalité dans les modèles ARMA. Lieu: Thèse de doctorat réalisée en cotutelle. Université Montpellier II et Université de Montréal. Date de soutenance: 16 décembre 2002 à l’Université de Montréal. Résumé: On construit un test d’ajustement de la normalité pour les innovations d’un modèle ARMA(p,q) de tendance et moyenne connues, basé sur l’approche du test lisse dépendant des données et simple à appliquer. Une vaste étude de simulation est menée pour étudier ce test pour des tailles échantillonnales modérées. Notre approche est en général plus puissante que les tests existants. Le niveau est tenu sur la majeure partie de l’espace paramétrique. Cela est en accord avec les résultats théoriques montrant la supériorité de l’approche du test lisse dépendant des données dans des contextes similaires. Un test d’indépendance (ou d’indépendance sérielle) semi-paramétrique entre des sous-vecteurs de loi normale est proposé, mais sans supposer la normalité jointe de ces marginales. La statistique de test est une fonctionnelle de type Cramér-von Mises d’un processus défini à partir de la fonction caractéristique empirique. Ce processus est défini de façon similaire à celui de Ghoudi et al. (2001) construit à partir de la fonction de répartition empirique et utilisé pour tester l’indépendance entre des marginales univariées. La statistique de test peut être représentée comme une V-statistique. Il est convergent pour détecter toute forme de dépendance. La convergence faible du processus est établie. La distribution asymptotique des fonctionnelles de Cramér-von Mises est approchée par la méthode de Cornish-Fisher au moyen d’une formule de récurrence pour les cumulants et par le calcul numérique des valeurs propres dans la formule d’inversion. La statistique de test est comparée avec celle de Wilks pour l’hypothèse paramétrique d’indépendance dans le modèle MANOVA à un facteur avec effets aléatoires.
[PDF écran] 2.5M (avec hyperliens et programmes Fortran et C++). Cette version PDF est très intéressante. Elle contient tous les programmes Fortran et C++ des simulations (presque 15000 lignes). Il y a aussi un programme Javascript inclus dans le premier article qui permet d’effectuer le test “en direct” (voir page 49, Javascript Application). Elle contient aussi des hyperliens facilitant la lecture. A visionner en mode plein-écran.
[MathML] 4.9M (Nécessite Mozilla ou Netscape 7.0. Temps de chargement assez long, patientez …). [MathML.gz] 318k (Les fichiers MathML contiennent les programmes Fortran et C++). MathML est une nouvelle technologie révolutionnaire qui permet de rechercher des expressions mathématiques dans le texte (et les copier-coller dans d’autres applications comme Mathematica). Les formules ne sont plus sous la forme d’images.
The R Package groc for Generalized Regression on Orthogonal Components
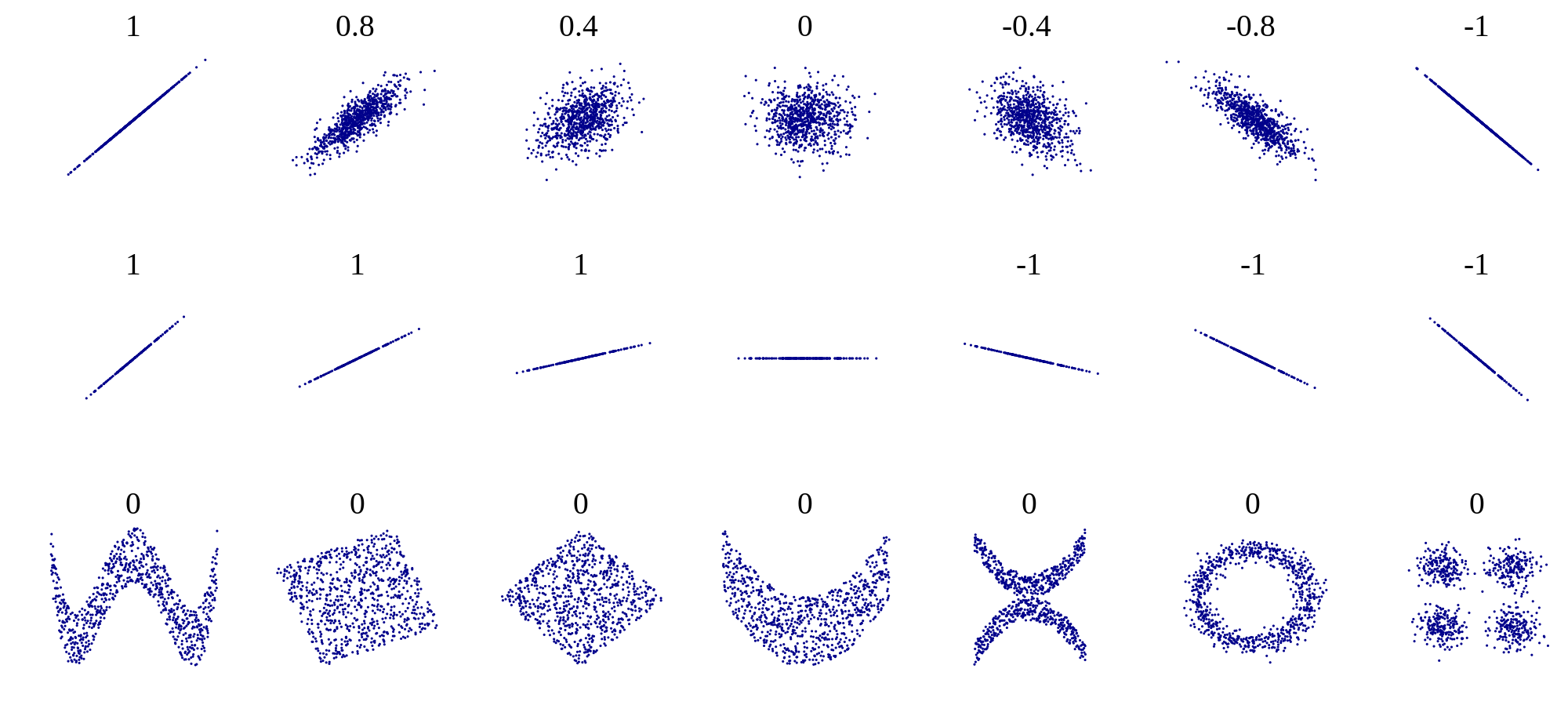
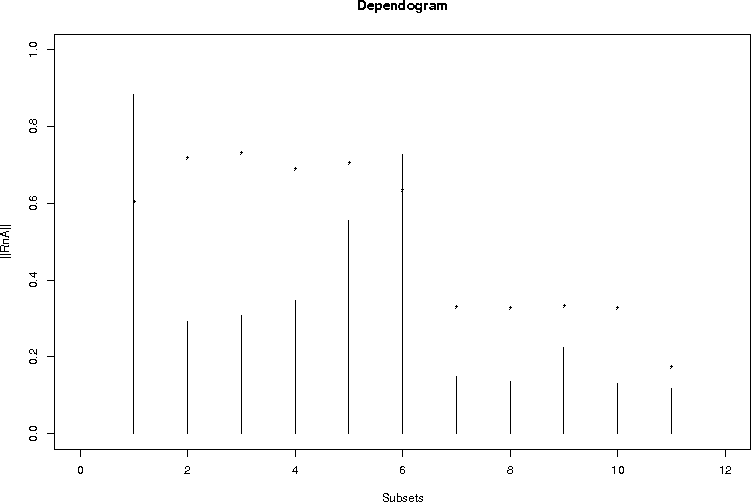
IndependenceTests (with Bilodeau M.). (Mutual and serial) Non-parametric independence tests
between random vectors and for categorical data. cran.r-project.org/package=IndependenceTests
AnalyzeFMRI (initiated by Marchini, J.). Functions for I/O FMRI data in various formats and for treating brain
images with ICA methods. Visualization. cran.r-project.org/package=AnalyzeFMRI
ConvergenceConcepts (with Liquet, B.). Check and visualize convergence of a sequence of random
variables in law, in probability, in r-th mean and almost surely.
cran.r-project.org/package=ConvergenceConcepts
asympTest (with Coeurjolly J.F., Drouilhet R. and Robineau J.F). One and two samples parametric tests based
on an asymptotic approach. cran.r-project.org/package=asympTest
nortestARMA (with Duchesne P.). Estimating the mean and its effects on Neyman smooth tests of normality
for ARMA models. cran.r-project.org/package=nortestARMA
TRSbook (with Drouilhet R. and Liquet B.). Functions and Datasets to Accompany the Book “The R Software: Fundamentals of Programming and Statistical Analysis”. cran.r-project.org/package=TRSbook
LeLogicielR (with Drouilhet R. and Liquet B.). Functions and datasets to accompany the book “Le logiciel R: Maitriser le langage, Effectuer des analyses statistiques” (French). cran.r-project.org/package=LeLogicielR
Some Associated Publications or Talks
The R Package groc for Generalized Regression on Orthogonal Components
9th International Conference of the ERCIM (European Research Consortium for Informatics and Mathematics) Working Group on Computational and Methodological Statistics (CMStatistics) (2016)
Lafaye de Micheaux P, “Multivariate Methods for the Treatment of High Dimensional Complex Neuroimaging Genetics Data”
2013 Mitacs Accelerate Research Internships Program ($30,000)
Lafaye de Micheaux P, Laliberté G, Harlouchet I, _“Optimization of Olfactory Fingerprint Analysis Algorithm”
2013 NSERC Research Tools and Instruments ($28,143)
Lafaye de Micheaux P (Lead CI), Granville A, Polterovich I, Patera J, Owens R, Lessard S, Murua A, Perron F, “Computational Resources for Research in Mathematics and Statistics”
Lafaye de Micheaux P, “Goodness-of-fit Testing and Independent Component Analysis with
Applications to Cognitive Neuroscience”
Grenoble Institute of Technology (Bonus Qualité Recherche) grant (€122,880)
Achard S, Coeurjolly J-F, Lafaye de Micheaux P, Rivet B, Sato M, “MoDyC project (Modelisation of Dynamical Brain Activity)”.
Research Opportunities
⇥ RESEARCH OPPORTUNITIES FOR POSTGRADUATE STUDENTS
I consider myself a Statistician/Data Scientist. What does it mean (for me)? It means that I am interested in:
developing (or using) new statistical techniques and software packages;
using (potentially advanced) mathematics or probability;
and also using High Performance Computing;
in order to solve real life practical problems;
involving (potentially complex and big) data sets.
For example, I have been using Linux (and bash scripting, sed, awk, emacs, etc.) since 1997 . I am currently using RAIJIN to analyse massive neuroimage data sets. My main interests in terms of applications are in Science and Engineering. I have a particular expertise and interest in Neuroscience (but also in Raspberry Pi). I am interested in any sort of Mathematics if you can show me that there will be some connection with Statistics.
I suggest that you poke around my website to see the sorts of topics I work on. Look at my publications and at the Masters or PhD theses of my past students. Please note that I’m not particularly interested in finance or economics. There are some excellent researchers in our school on both topics, but I’m not one of them. I could however consider jointly supervising you if my colleague at the Business School Benjamin Avanzi accepts to be part of this joint supervision.
You must have a strong background in statistics/mathematics/econometrics and good programming skills (preferably in R, C/C++, or Python, with experience in Linux). It is essential that you have studied some matrix algebra, multivariate calculus and optimization. You should be familiar with reproducible research practices including using, e.g., Seafile, Gogs and Rmarkdown.
If you are still interested in doing research (a Ph.D. or a Master’s or an Honour’s degree) with me and/or other members of our research projects and if you have the necessary qualifications and background (see below), feel free to contact me via email attaching the following documents in PDF format (I will disregard documents in any other format):
Your resume (with a photo; I like to put a face to a name).
A copy of your academic transcripts.
Describe your previous research (if you did some) in less than a page (a bit of technique and put it in a broader context).
A brief statement of what area / problems you would like to work on, and what attracts you to this group:
Why do you want to study here? With me? (e.g., have a look at my publications)
What are your skills (e.g., computing, theory, applications)?
What are your main interests (e.g., computing, theory, applications)?
Why do you want to do a thesis? What are your plans for after (e.g., find a job in the academia, private sector)?
Discuss potential things you could work on with me.
At least one referee (e.g., former supervisor, teacher) details: name, position, university, email address.
Before our first meeting (face to face, phone, video), think about:
What do you want to discuss with me?
How do you envision our interaction?
Do you have any question for me?
I will support your application as long as:
(a) you addressed all the points above;
(b) you are indeed an outstanding student;
(c) your project proposal is aligned with my research interests.
Please note that, unless specifically advertised, I do not offer scholarships myself.
So, please first:
use the UNSW HDR self-assessment tool, which will give you an indication of your admission eligibility and competitiveness for a scholarship.
Scholarships are available for talented and enthusiastic students looking to study for a Ph.D. or a Master’s degree. Nevertheless, they are highly competitive: to be in the running, you need to demonstrate that you are among the top students in your cohort. If you wish to be considered for a scholarship, you will need to apply separately. (Unless advertised, our group do not offer scholarships.)
If you are an undergraduate student interested in doing Honours in Statistics, we are looking for students with a strong background in statistics and good computational skills. If that’s you, then get in touch.
My Teaching
Current
I am a teaching instructor for the following courses at UNSW Sydney:
2018
MATH1041: Statistics for Life and Social Science (48h)
MATH3821: Statistical Modelling and Computing (36h)
2017
MATH1041: Statistics for Life and Social Science (48h)
R/Shiny : Introduction to RShiny, at French National School of Statistics and Analysis of Information (ENSAI) (9h)
2016
MBDINF14 : Programming with Big Data in R using Distributed Memory, at ENSAI (45h)
2015
MBDSTA02 : Statistical Inference and Hypothesis testing, at ENSAI (18h)
STT2700 : Mathematical Statistics and Data Analysis, at Université de Montréal (39h)
STT6300 : Large Sample Techniques, at Université de Montréal (37h)
2013
STT2400 : Linear regression, at Université de Montréal (36h)
STT6415 : Regression Analysis, at Université de Montréal (42h)
2012
STT1700 : Introductory Statistics, at Université de Montréal (36h)
Industry
Consulting work for the private sector
Industrial Experience
2016 Statistical consultant for BNP Paribas, which is one of the largest banks in the world, with a presence in 75 countries. I applied Deep Learning algorithms.
2014 University supervisor for a student working (under a Mitacs internship) at Odotech, which is an environmental company specialized in real-time monitoring of gas pollutants. Optimisation of an algorithm that analyses olfactory fingerprints.
2011 Statistical consultant for Olea Medical. Identification of predictors for stroke.
2008 Shareholder and co-founder member (with J.-F. Robineau and others) of the start-up CQLS whose aim is to analyze biotechnology data. Operations have now ceased.
2007 Statistical consultant for the company Minvasys, which conceives drug eluting stents. Computation of necessary sample size for clinical trials.
2006–2007 Statistical consultant for the company BioArtificial Gel Technologies. This company, which was a dermo pharmaceutical canadian private company based in Montreal, developped and marketed systems for the progressive release of active agents based on a hydrogel technological springboard. Operations have now ceased.
Here are some nice references on Deep Learning:
Neural Networks and Deep Learning is a free online book
Jürgen Schmidhuber’ webpage on Deep Learning
New book by Y. Bengio
COMP9444 at UNSW
Some summer schools with slides and videos:
Deep Learning Summer School, Montreal 2015
Deep Learning Summer School, Montreal 2016
Deep Learning (DLSS) and Reinforcement Learning (RLSS) Summer School, Montreal 2017



































 . I am currently using
. I am currently using 




